サンスクリット・チベット語の電子テキストの転写について
On the Transliteration of E-Texts in Sanskrit and Tibetan
(version Nov 29, 1998)[Menu]
1 はじめに
サンスクリット語・チベット語などで書かれたテキストを 電子データとして入力・公開することが盛んに行われている。 この傾向は今後さらに強まることが予想され、また、 このような形で公開されている電子テキストを研究に取り入れることが 今後広く行なわれるようになることは想像に難くない。
これらの電子テキストをどのような形で扱うにせよ、 必ず問題になってくるのは文字コードの問題である。 サンスクリット語を表記するのに最も一般的であると思われるは デーヴァナーガリー文字であり*1、 またチベット語を表記するのはチベット文字であるが、 一般的な計算機環境はこれらの文字に対応しておらず、 これらの言語のテキストを扱うためには何らかの転写方式を 用いるのが一般的である。しかし現在のところ、 すべてのプロジェクトで共通した転写方式というものが存在して おらず、それゆえ すべての電子テキストを統一的に扱うのは非常に困難な状況にある。
そこで我々は世界じゅうで行なわれている サンスクリット語・チベット語関連の電子テキスト 構築プロジェクトにおいて用いられている転写方式に関して、 それぞれの転写方式の規則的な特徴についての調査を行い、 それぞれの転写方式を自動的に判別することが可能かどうかの 実験をおこなった。またサンスクリット語については、 転写方式の規則的な特徴が明確に判別できない転写方式についても 自動的な判別ができるようにするため、対象言語の言語的特徴に 注目して、その転写方法が何かを推定して転写方式を判別する 実験もおこなった。
我々は、このような実験を通じて、いろいろな転写方式が自動的に 判別するできるようになること、また、それによって すべての転写方式で用意された電子テキストを統一的に扱うことが 可能となるための足掛かりを築いて行きたいと考えている。
2 サンスクリット語
2.1 はじめに
古典サンスクリット語については、 ほぼ業界標準と呼んでよい ダイアクリティカルマーク付きアルファベットへの転写表記方法が 存在している。

[図1: サンスクリット語における転写方法の一部]
この転写方式の一部を図 1に示す。
しかし一般的な計算機環境では、 ダイアクリティカルマーク付きのアルファベットを表記することが 困難なため、ダイアクリティカルマーク付きアルファベットに対する 再度の代替表記を行なうことが一般的である。
2.2 転写方法について
ダイアクリティカルマーク付き文字を他の表記
で代替する手法(例: ā を A と表記する)と、
ダイアクリティカルマーク付き文字を非 ASCII コード部分に
割り当てる手法がある。
非 ASCII コード部分を用いるものについては、文字コードが 一般的な計算機環境における日本語の文字コードと重複してしまう ことがあり、日本語との共存ができないという問題がある。 それゆえ日本では現在のところ、 特定のワープロソフトを使うなど、特定の 計算機環境に依存する形でしか使用することができない。
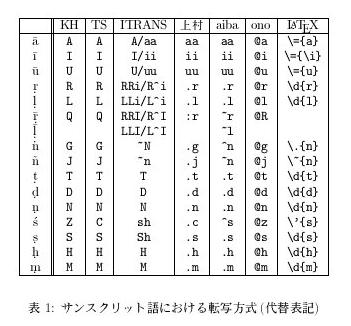
[表1: サンスクリット語における転写方式(代替表記)]
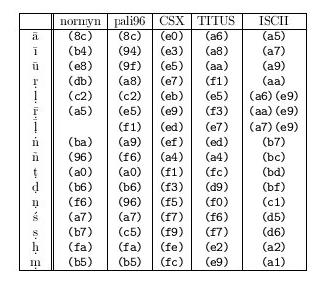
[表2: サンスクリット語における転写方式(非ASCIIコード)]
表 1 および
表 2 に、本稿で参照した転写方式の
一覧の一部を示す。非ASCII コードの一部を用いる転写方式については、
非ASCIIコードはそのままでは表記できないため、
本稿ではその文字コードを 16 進数で表現したものを括弧で囲んだ
(b5) のように表記する。
このそれぞれの方式について、順に簡単な説明をおこなう。
2.2.1 他の表記で代替する方法
KH,TS
KH は Kyoto-Harvard 方式、また TS は Tokyo Standard 方式の
略称である。
両者とも文字の下にピリオドが付く子音は大文字で表記する。
また、それ以外のダイアクリティカルマーク付きの文字についても、
適当にアルファベットの大文字を割り当てている。
この両者は ṅ/ñ を表記するために
G/J という文字を用いている点に特徴がある。一方で、
これら両者の相違点は ś の表記の違いしかないため、
この両者を区別することは場合によっては非常に困難である。
ITRANS Avinash Chopde 氏ら[6] による転写方式。 文字の下にピリオドが付く子音を大文字で表記する点は KH,TS とほぼ同じであるが、一部の文字に対して 非常に特徴的な表記をおこなっている。 この特徴的な部分について表 3 に示す。

[表3: ITRANS における表記の特徴]
上村, aiba 上村は東大の上村氏が、また aiba は我々が用いている 転写方式である。 母音を重ねることによって長母音を表記する点、また ダイアクリティカルマーク付きの文字を表記する際に 子音のアルファベットの前にピリオドを置くことがある点で、 両方の転写方法は類似している。 しかし両者のあいだには以下のような方針の相違が見られる。
- 上村では ダイアクリティカルマーク付きであることを示すために ピリオドを用いる
- aiba は ダイアクリティカルマークと類似した記号を アルファベットの前に置く
.r/.l/.t/.d/.n/.s と表記されるが、これ以外の
文字については相違が見られる。
ono 広島大学などで用いられている転写方式だが、
一覧表として参照できたのは小野氏[8] によって書かれたもの
だけであったため、ここでは ono と呼んでいる。
この表記方法の特徴であるが
「ダイアクリティカルマーク付き」であることを示す記号として
@ を用いている点である。
LaTeX LaTeX とは
Lamport 氏[9] による、文書組版システム TeX の
マクロパッケージである。この LaTeX でも「アクセント記号」
としてダイアクリティカルマーク付きアルファベットを記述する
ことができる。これらの記号を記述する場合に \={a} のよう
に \ に始まる一連のシーケンスを用いているところに
特徴がある。
2.2.2 非ASCIIコードの一部を利用するもの
normyn,pali96 normyn は Norman氏[10]が、 pali96 は逢坂・山崎氏ら[11]が配布しているフォント およびデータで用いられている文字コードである。 それぞれ特殊文字を示すため 任意の文字コードを使用しており、両者の判別は非常に困難である。 それぞれ特殊文字を示すため独自のコード割り当てをしているため、 両者の判別は非常に困難である。
CSX Smith 氏[7] らが用いている転写方式。
TITUS Gippert 氏[11] らによる転写方式。
ISCII ISCII はインドにおける国内標準規格であるらしく、インド国内では 最も一般的な表記方法のようである。 ISCII では子音の接続および a 母音つき子音の扱いが 他の方式および一般的なローマナイズで想定されている規則とは 異なっており、たとえば aṣṭa を表記する際に、 表4のようなコード配置となる。

[表4: ISCII におけるコード列]
すなわち子音の後に母音 a が付く場合その母音 a は表記せず、また 母音が後続しない子音には「母音がつかないこと」を示す記号 (ここでは便宜的に \( \triangleright \) として表現した) を 付与する、といった内容になっている。これは デーヴァナーガリー文字に規範を取っているのだが、 逆にローマナイズ表記を規範としている他の転写方式との 混在が難しいという問題がある。
2.3 規則を用いた転写方式の自動判別
すでに2.2節でも触れたように、 それぞれの転写方式にはそれぞれ独自の規則・特徴がある。
その規則・特徴を利用することによって、 機械的な転写方式の判別がどの程度可能であるかの 実験をおこなった。なお非ASCIIコードを用いた方式については 文字コードの配列の規則を見つけることができないため、 ここでは実験対象としない。
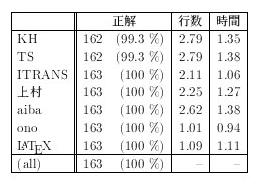
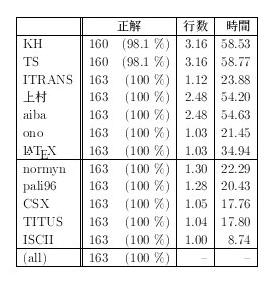
実験内容 テキストとしてはBhagavadgītā[2]を使用した。 このテキストを 10 行(約5偈)ごとに区切った 163 データを それぞれの転写方式に変換したものを用意し、それに対して 2.2節で述べたような規則・特徴を判別させる プログラムを用いて自動判別させる実験をおこなった。
結果 表5に結果を示す。 この表において「行数」とは判別結果が出るまでに要した行数の 平均値であり、また「時間」は判別にかかった所要時間*2 の平均値である。
[表5: サンスクリットにおける転写方法判別の結果 (1:規則)]
このことから、 かなりの精度で自動判別が可能であることがわかる。 正解にならなかったデータは KH, TS でそれぞれ一例のみで あった。
判定できなかった部分は KH, TS で共通している。調査してみたところ、 その部分には KH と TS を識別する ś が出現していないため 両者の判別ができなかったことがわかった。 この場合、両者は同じものとして扱っても何の問題もないため、 実質的には完全に判別ができたと考えてもよいだろう。 また機械的な判別に必要なデータ量の平均が 2-3 行となっているが、 このことから、ほぼ1-2偈程度の情報で自動判別が可能であることがわかる。
2.4 言語的特徴を利用した転写方式の推定
前節ではそれぞれの転写規則を利用した自動判別の実験をおこなった。 その結果、代替表記を用いる手法のものに ついては KH/TS のような非常に類似した事例を除けば、 かなりの確率で自動判別が可能であることがわかった。 しかし 非ASCIIコード部分に文字コードを割り当てる手法のものについては、 この方法では対応できないことが問題となった。
そこでサンスクリット語の言語的特徴を抽出し、その言語的特徴を 利用することによって転写方式の推定をおこなうことにしたい。
2.4.1 サンスクリット語の言語的特徴の抽出
我々の目的は転写方式の判別に必要な言語的情報の抽出である。 そのために必要な言語的情報ということで、 我々は以下のような情報を抽出することにした。
- ある文字の前後に来ることが多い文字はどの文字か
サンスクリット語では、単語列としてはこの例の左側のようになる場合に、 文としては右側のように表記されるという特徴がある。 そこで我々はこの特徴を利用する。
文字連接情報の取得 Rāmāyana を用いたデータ解析をおこない、 文字の連接に関する情報を採取した。電子データは Smith氏らが公開しているもの[4] を用いた。このデータはもともと 京都大学の徳永氏[3] を中心として構築されたもので あり、データ管理の点でもそちらの方が行き届いていることは確かであるが、 徳永氏らのデータは ṅ/ñ/n を同一化するなどの特殊な配慮がなされているため、 今回の我々の目的には合わないと判断した。
具体的の情報の採取であるが、たとえば以下のような文があったとする。
dharmakṣetre kurukṣetreこの文を以下のように区切る。
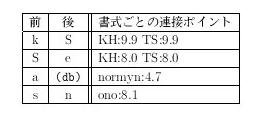
dh a r m a k ṣ e t r e k u r u k ṣ e t r eこのような区切りをもとにして「dh と a は接続している」 「a と r は接続している」のようなデータを、転写方法ごとに 採取するという単純な方法をとった。 採取した情報の一部を表6に示す。 この例では、連接の組と書式ごとに、出現回数に基づいた ポイントをつけてある。*3
[表6: サンスクリット語における接続テーブルの一部]
今回の実験では、このような文字の組合せが 3262 組取得できた。
2.4.2 転写方法の推定による自動判別の実験
前節で述べた方法で抽出した情報を用いて、 電子テキストの転写方法の推定に関する実験をおこなった。
方法 まず具体的な推定の方法について簡単に説明する。 以下のようなTS 形式の入力があったとする。
kSetreこの文を以下のように区切る。
k S e t r eそして、それぞれの連接部分、たとえば k と S、S と e .. といった 全部の組合せの連接ポイントを書式ごとに合計していく。 表9を用いて k S e 部分の ポイントの計算をしてみると、 k S 部分は KH と TS の両方で 9.9 点、 S e 部分は KH と TS の両方で 8.0 点となり、 KH と TS の両方が合計 17.9 点(他の書式は 0 点)となる。 このようにして、どの書式が最もそれらしいかを数値的に 表現し判断する。
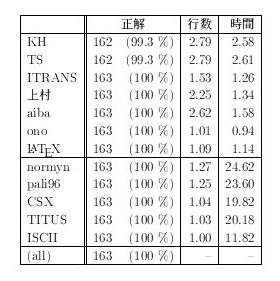
結果 2.3節でおこなった実験と同じ条件での実験を おこなった。推定の内容であるが、ある特定の転写方式における ポイントの合計が、他のすべての転写方式でのポイントの合計よりも 与えられた閾値(具体的には10点)以上大きくなったときに 転写方法の推定が終わる、という簡単なものである。
[表7: サンスクリットにおける転写方法判別の結果 (2:推定)]
こうして行なった実験の結果を表7 に示す。この実験では2.3節で用いた規則による判別は 行なわず、 連接ポイントを用いた推論のみによる判別をおこなっている。
[表8: サンスクリットにおける転写方法判別の結果 (3:規則・推定)]
2.3 節で用いた判別と、 本節で用いた文字ポイントによる推定の両方を組み合わせた方法による 判別実験の結果を表 8 に示す。 推定のみを用いた場合、KH および TS の精度が若干低下してしまう 問題が生じてしまうが、規則的な判別を加えることによって 高精度の判別が行なわれるようになった。
また判別にかかる所要時間についても、規則で判別可能なものに ついては規則的に処理してしまうことにより、全体的な所要時間が 大幅に短縮した。
このことから、規則・推定という両方の判別方法を組み合わせる ことによって、精度・速度の両方について効果があることが 判明した。
3 チベット語
3.1 はじめに
チベット語は、サンスクリット語の場合とは異なり、 ダイアクリティカルマーク付きのアルファベット表記に転写する際に、 業界で統一的となっているような方法が存在していない。 主な転写方法としては、以下のようなものがあげられる。
- アメリカ議会図書館 (Library of Congress) で用いられている表記
- Chandra Das の辞書[12]、また「東北目録」で用いられている表記

[図2: チベット語における Das の転写方法の一部]
これらの転写方式うち、Chandra Das が用いている転写方法の 一部を図2に示す。*4
3.2 転写方法について
[表9: チベット文字転写方法の一覧(部分)]
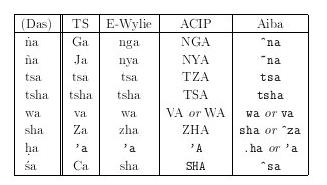
転写方法が異なる箇所を中心にした転写方式の一覧を 表9に示す。 この表にあげられている、それぞれの転写方式およびその特徴について 簡単に述べる。
TS Tokyo Standard 方式の略称。 これはアメリカ議会図書館で用いられている表記を、 サンスクリット語の TS と同じように再転写したものである。
E-Wylie
Wylie 氏ら[14]によって提案された転写方式。
小文字の ng/ny/zh の使いかたが特徴的と思われる。
ACIP
Asian Classics Input Project (ACIP)[15] で用いられている
転写方式。
主に大文字を使用する点に特徴がある。基本的には E-Wylie の書式を
大文字化したものとも見ることができるが、TZ および
TS と
いった転写方法に特徴がある。
aiba
Chandra Das の辞書[13]、また「東北目録」で用いられている表記
を再転写したもので、サンスクリット語の場合と同様に
我々が用いている方式である。
この方式は .h という記号を使うところに特徴がある。
また ṅ/ñ などの表記も独特であるが、
これはサンスクリット語における転写方式と同様に
「ダイアクリティカルマークと比較的類似した記号をアルファベット
の前に置く」という方針を取った結果である。
3.3 機械的な転写方式の判別
表9に示した各転写方式の特徴に基づく自動判別を試してみる。
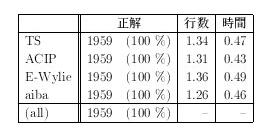
テキストとしては ACIP の Lalitavistara[5]を用いた。このテキストを それぞれの書式に変換したものを用意し、それぞれのテキストを どの程度判別できるかに関する実験をおこなう。
[表10: チベット語における転写方法判別の結果]
結果 表10に結果を示す。 入力データほぼ 1-2 行(デルゲ版の木版にすると 1/3 行程度)で 確実に書式の判別が可能であることがわかる。
4 考察
まずサンスクリット語の自動判別について述べる。 規則および言語的特徴の両方を利用することにより、 いずれの転写方式に対してもかなりよい精度で判別できて いるといえる。
ところで実際に転写方式自動変換システムを作成しようとした場合、
実は転写方式の判別が必要ない場合もある。たとえば KH と TS は
ś を Z と書くか C と書くかという
相違しかないわけだが、この場合「Z であっても C であっても
ś と認識する」としておけば両者を判別する必要が
なくなる。一方で、たとえば KH は ch で ch を表記するが
ITRANS で ch と書くと c のことになるため
KH と ITRANS は判別する必要がある。この KH と ITRANS のように、
同じ表記が別の文字を指してしまっている事例の一部を
表 11 に示す。*5
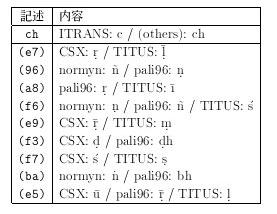
[表11: サンスクリット語の転写方式におけるコンフリクト一覧 (一部)]
この表から、代替表記をする各転写方式については、 ITRANS という 例外を除けば、転写方式を識別する必要がないことがわかる。 しかし非ASCIIコードを用いる各方法については、コードの割り当てが 互いにどこかでコンフリクトを起こしているため、転写方式の判別が どうしても必要となる。
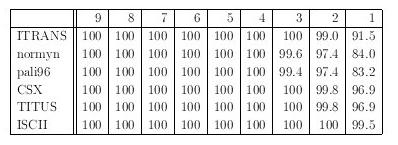
[表12: データ量ごとの精度の一覧]
また自動判別プログラムの作成の前に確認しておくことがある。 判別プログラムに与えられるデータの量と判別精度との関係である。 すでに実験してきたとおり、ある一定量以上のデータが与えられた場合は ほぼ完璧といえる精度で転写方式の判別が可能となるのだが、 たとえば1偈程度の情報しか与えられなかったときの判別精度に関する 調査は必要であろう。
そこで自動判別プログラムに与えるデータ量を変化させたときの 判別精度に関する実験をおこなった。 結果を表12に示す。 表の上に書かれている数字が判別プログラムに与えたデータ行の数であり、 たとえば 4 と書かれている欄は判別プログラムに 4 行(2偈分)だけ データを与えたときの判別精度を % で示している。 この表によると、データ量にして 2 行(1偈)程度の分量の情報だけで、 ITRANS, CSX, TITUS なら 99% 、ISCII なら 100% 、また最も精度が 低くなってしまう normyn, pali96 でも 97% 程度の判別精度が あることがわかる。それゆえ、おそらく実用的に十分な判別精度を持った 自動判別プログラムが作成可能であると考えられる。
チベット語の自動判別についてであるが、 現在まで我々が蒐集した転写方式の数がそれほど多くないこともあり、 かなり容易に判別が可能であることが判明した。

[表13: チベット語の転写方式におけるコンフリクト一覧]
相容れない転写文字の一覧を表 13 に示す。 この部分にさえ気をつければ、転写方式を統一的に扱うことはさほど 困難ではないといえる。
5 おわりに
すでに我々は、 それぞれの転写方式の転写内容の一覧表を作成して ネットワーク経由で公開している[16]。 また本稿で我々が述べたサンスクリット語・チベット語の 自動判別を実行するプログラムを作成・公開する予定であるが、 これはまだ現在のところ試作段階に留まっている。
今後の課題について述べる。 我々が本稿で取り上げた転写方式以外にも、 まだ多くの変換方式が世間には存在していると考えられる。 それゆえ、今後さらに多くの転写方式を蒐集し、それらの 自動判別に関する調査および実験を行なっていくことが 課題としてあげられる。
また本稿で我々はサンスクリット語の言語的特徴を利用しての 転写方式の推定をおこなったが、この実験の際に抽出・利用した データはそれなりに大きいものになってしまっている。 今後、このような推定ルーチンを含む転写方式統一プログラムを 作成・公開するに当たっては、このようなデータのサイズは 小さければ小さいほど望ましいように思われる。そこで 精度が落ちないことに留意しながら、転写方式の推論用の データのサイズを可能なかぎり小さくする作業も 今後の課題として考えている。
[註]
- *1
- しかし学術論文等では
サンスクリット語を表記する際にデーヴァナーガリー文字を
使うことは、技術的に可能である場合であっても敬遠される。
- *2
- 筆者が実験に使用した計算機における計測値で、1.0 が 1/100 秒である。
- *3
- 具体的には出現回数に log をかけてある。
- *4
- 本稿では便宜上、この Chandra Das の転写方法を用いる。
- *5
- ISCII はコードの使い方が他とは異なっているため、ここでは除外した。
参考文献
- [1]
辻直四郎,
『サンスクリット文法』,岩波書店(岩波全書 280),1974.
- [2] Bhagavadgītā, URL: ftp://ftp.ucl.ac.uk/pub/users/ucgadkw/indology/texts/bhagavadgita.zip
- [3] Muneo Tokunaga, ``The digitalized texts of Rāmāyana'', 1996. URL: ftp://ccftp.kyoto-su.ac.jp/pub/doc/sanskrit/ramayana/
- [4] John D. Smith, ``The digitalized texts of Rāmāyana'' (based on the versions typed up by Prof. Tokunaga), 1996. URL: ftp://bombay.oriental.cam.ac.uk/pub/john/text/ramayana/
- [5] Lalitavistara,
kd0095e.incin ACIP release 2.- [6] Avinash Chopde, ITRANS , URL: http://www.aczone.com/itrans/;
``ITRANS transliteration map'', 1991-4. URL: http://reality.sgi.com/atul/sanskrit/dict/itrans.html- [7] John D. Smith, URL: ftp://bombay.oriental.cam.ac.uk/pub/john/software/fonts/csx+/CSX+.def
- [8] Motoi ONO, ``Explanatory Remarks'', 1997. URL: http://www.logos.tsukuba.ac.jp/~nagasaki/dharmakirti/hpvorwor.html
- [9] Leslie Lamport, 『文書処理システム \LaTeX 』,アスキー出版局, 1990.
- [10] ``the final versions of Professor Norman's fonts'', URL: ftp://ftp.cac.psu.edu/pub/jbe/fonts/NORMAN/
- [11] Yumi OUSAKA and Moriichi YAMAZAKI, ``RESEARCH PROJECT : Personal Computer Analysis of Middle Indo-Aryan, Production by Computer of Indexes to Pali Tipitaka Texts'', 1997, URL: http://www.sendai-ct.ac.jp/~ousaka/
- [12] ``Thesaurus Indogermanischer Text- und Sprachmaterialien Zubehör (Software etc.)'', URL: http://titus.uni-frankfurt.de/software/fonts/titidgft.htm
- [13] Chandra Das, ``Tibetan-English Dictionary'', Calcutta, 1902.
- [14] Yoichi Fukuda, The Toyo Bunko, ``Extended Wylie Method of the transcription of Tibetan characters'', URL: http://www.toyo-bunko.or.jp/Tibetan/EWylie1.html
- [15] The Asian Classics Input Project, URL: http://acip.princeton.edu/
- [16] 相場徹, 「サンスクリット・チベット語などにおける 転写方法/文字コード割り当て の一覧」, 1998. URL: http://www.vacia.is.tohoku.ac.jp/member/aiba/indo/codes.html
- [2] Bhagavadgītā, URL: ftp://ftp.ucl.ac.uk/pub/users/ucgadkw/indology/texts/bhagavadgita.zip